Intro to dbt for Healthcare

This post builds on a presentation my co-founder Coco Zuloaga created a few years ago to help healthcare organizations understand what exactly dbt is and why it's a critical tool for healthcare data and analytics teams. You can find Coco's presentation at the bottom of this post.
Healthcare has always been a laggard in terms of adopting new technologies. Estimates vary, but often put healthcare 1 to 2 decades behind other industries. Of course, the classic example is the fax machine, which is still very much alive in healthcare today.
And it's no different with dbt. While we see 80-90% of venture-backed healthcare startups adopting dbt, it's closer to 10-20% for traditional health systems, payers, and pharma.
Over the past several years, we've come to believe that dbt is an indispensible tool for healthcare data teams. And while we love dbt, we don't have any commercial relationship with them, so our bias is born out of love for the tool, not any financial incentive.
For many healthcare organizations, data engineering looks very much like it did in the early 2000s: thousands of SQL files saved in file folders across shared drives and local computers, never version-controlled, and orchestrated via stored procedures.
At the highest level, a data team without dbt is like a software engineering team without an IDE or git. Developing, testing, and collaborating becomes so painful it's practically impossible. Errors are common, iteration is slow, and everyone is working on their own version of the truth.
The good news is that dbt solves all of these problems and it's open source and free to use. They also have a paid version with advanced security and collaboration, among other features. But at Tuva we almost exclusively use the open source version.
So how does dbt actually solve these problems? Put simply: dbt brings software development best practices to data engineering.
1. Common Framework
At the foundational level, dbt provides a common framework for organizing analytics code. The atomic unit is a dbt project. Every dbt project has the exact same set of files and folders by default. You use the files to configure how dbt interacts with your data warehouse and use the folders to organize your code. This consistency is simplifying and is similar to other software development frameworks, e.g. React, which is a web framework.
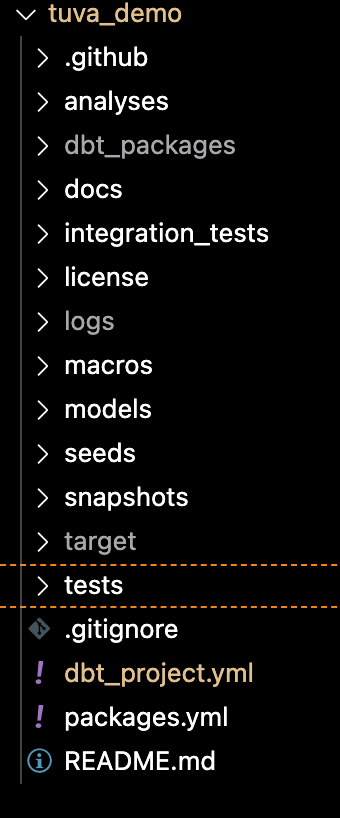
The image above is a dbt project, specifically the folder structure from our tuva_demo repository. It's worth briefly explaining a few components of the framework:
dbt_project.yml: This is the file you configure to connect dbt to your data warehouse and to tell dbt which database(s) and schema(s) you want to write data to.
models: This is the folder where all of your code is stored. These are SQL files that dbt executes when you run the project. dbt automatically infers the correct order in which to run each SQL file (i.e. it builds a directed acyclic graph behind the scenes). The end result is data tables and views that are created inside your warehouse.
seeds: This is the folder where all lookup tables are stored. These are CSV files that dbt loads into your data warehouse any time you run the project, which SQL files (i.e. models) can then reference. We use seeds all the time for terminology sets e.g. ICD-10 codes.
You can run any dbt project with a single command from the command line: dbt build.
2. Integration with Data Warehouses
If integrating your code with your data warehouse sounds trivial consider this: most data teams have hundreds or thousands of SQL files that must run in the exact right order. How do you program them to run in the right order and then actually run them so that they build data tables in your data warehouse?
Before dbt, data analysts would write SQL to create data tables and data marts and then this SQL would have to be refactored into stored procedures before it could be run and scheduled in production. Someone else, often engineers with little understanding of the SQL, would do the refactoring.
This hand-off is inefficient, because it slows down development and increases the probability of introducing errors. If you're a small team (1 or 2 people) working on a small number of projects, this inefficiency isn't a major problem. But it really starts to multiply as the size of the team and number of projects increase.
dbt eliminates the need for this hand-off by making it simple for data analysts to program and run code in their data warehouse. And dbt integrates with any modern data warehouse (Snowflake, Bigquery, Databricks, Redshift, DuckDB, Postgres, Azure Synapse, etc.).
3. Integration with Git
If you're like a lot of healthcare data teams you're probably not using git. There are two major downsides to not developing with git.
First, there is no version-controlled source of truth. With very small teams (1 or 2 people) this isn't a problem, but pretty quickly things can get out of hand, with different people on the team unwittingly working on different versions.
Second, without git you don't have a software development workflow. A traditional software development workflow helps ensure high-quality code can efficiently be committed and released. There's a reason pretty much all software engineering follows this process. From a high-level it looks something like this:
- Changes are developed on a new branch
- A pull request is created once changes are ready to be merged
- The pull request is reviewed by someone else and edits are made if necessary
- If everything looks good the code is merged to the main branch
- A release is cut including release notes
dbt integrates seamlessly with git, enabling all of this functionality and more. Beyond the workflow above, it's simple to setup automated testing that runs on every pull request. Automated testing streamlines the code review process. Any time a PR is opened the entire code base is tested automatically to see if the new changes run or not. If the run is successful, you can be more confident that there aren't any catastrophic errors in your new code, allowing you to merge code to main more confidently and rapidly.
4. Marries Code, Docs, and Data Quality Testing
Finally, dbt combines code, documentation and data quality testing in a single place - the dbt project. If you've worked in data engineering for any length of time you know the best you can typically hope for is comments in the code. But dbt takes documentation and testing to a whole new level.
dbt generates documentation directly from the code you write, creating data dictionaries and a DAG (directed acyclic graph). For example, you can check out the Tuva dbt docs here. The DAG in particular is enormously helpful, because it allows you to quickly see how changes in your code impact downstream tables.
Data quality tests, on the other hand, can easily be added to any column in any table. For example, it's easy to add a test that checks whether a column that is supposed to be the primary key on a table is in fact unique and not null. These tests can be customized to essentially test anything you can think of and will run every time your build your dbt project.
Getting Started with dbt
Organizations brand new to dbt often have a lot of questions, for example:
- How many projects / repos should we have?
- How should we organize our data model?
- How should we implement automated testing?
- How should we manage larger seed files?
If you're thinking about adopting dbt and you'd like to avoid the mistakes we made over the last several years, ping us on Slack or shoot us an email. We're happy to chat.